

MiniGPT-4--在线使用/本地部署--与图片对话
MiniGPT-4是什么?
GPT-4 已经发布一个多月了,但识图功能还是体验不了。
来自阿卜杜拉国王科技大学的研究者推出了类似产品 —— MiniGPT-4,大家可以上手体验了。
它能提供类似 GPT-4 的图像理解与对话能力,让你先人一步感受到图像对话的强大之处。
MiniGPT-4可以做什么?
它可以做的一些事情:
解释照片上的内容
发现问题并解决它们(例如:枯死的植物,如何处理)
为照片写诗
给你一个草图的 HTML/JS 代码(我实际上试过了,但它并没有真正起作用..)
为给定的照片写广告
为给定的膳食照片写食谱和购物清单
解释艺术
官网:https://minigpt-4.github.io/
体验地址:https://huggingface.co/spaces/Vision-CAIR/minigpt4
视频演示
通过先进的大语言模型增强视觉语言理解
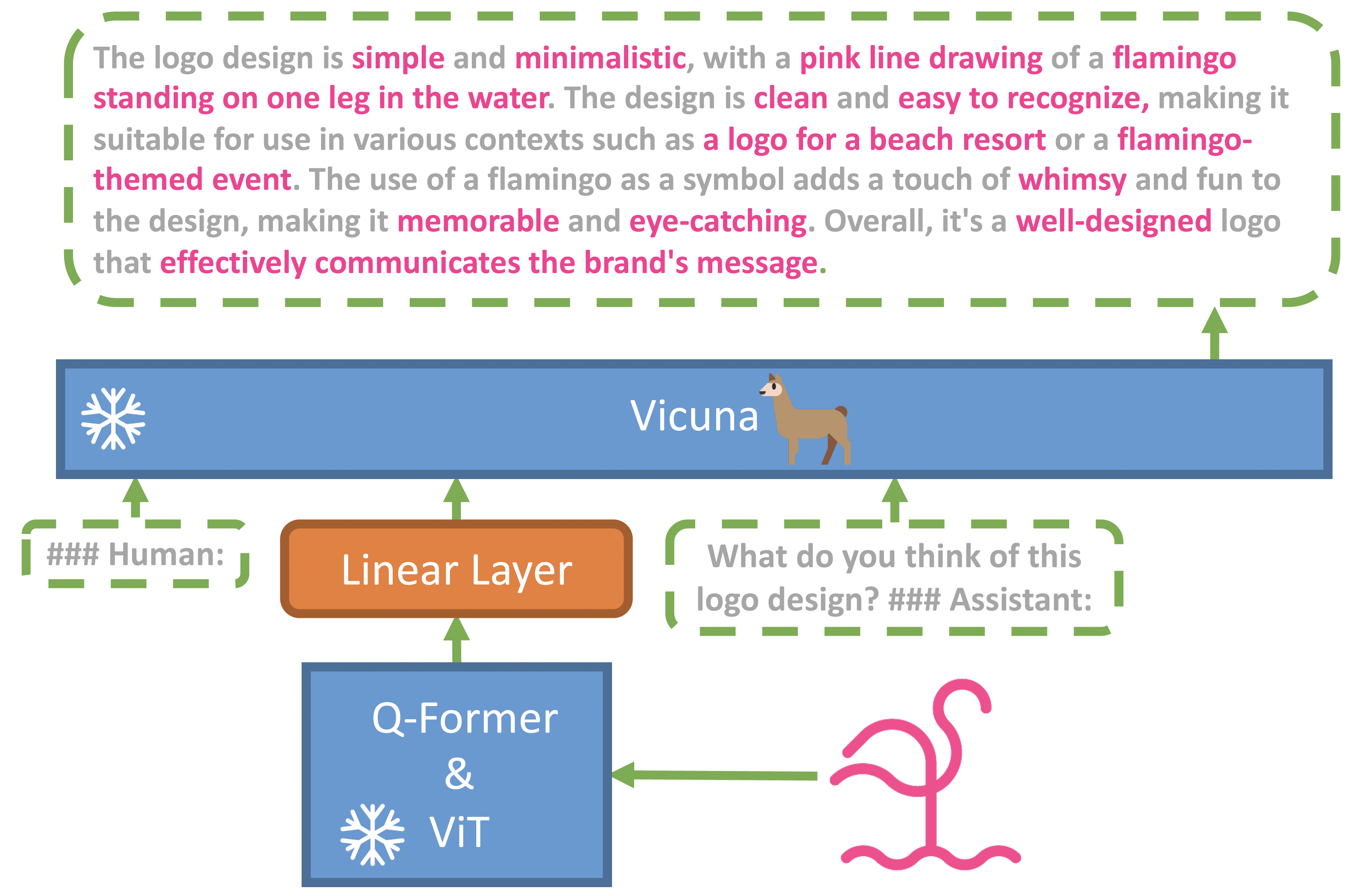
最近的 GPT-4 展示了非凡的多模态能力,如直接从手写文本生成网站和识别图像中的幽默元素。这些特性在之前的视觉语言模型中很少被观察到。我们认为,GPT-4 先进多模态生成能力的首要原因是利用了更先进的大型语言模型(LLM)。为了检验这一现象,我们提出了 MiniGPT-4,它通过仅使用一个投影层将冻结的视觉编码器与冻结的 LLM Vicuna 对齐。我们的发现表明,MiniGPT-4 具有类似于 GPT-4 展示的许多能力,如详细图像描述生成和从手写草稿创建网站。此外,我们还观察到 MiniGPT-4 中的其他新兴能力,包括根据给定的图像创作故事和诗歌、为图像中显示的问题提供解决方案、根据食物照片教用户如何烹饪等。在我们的实验中,我们发现仅在原始图像-文本对上进行预训练就可能导致不自然的语言输出,包括重复和句子片段化。为了解决这个问题,我们在第二阶段策划了一个高质量、对齐良好的数据集,以便使用对话模板微调我们的模型。这一步骤对于增强模型生成的可靠性和整体可用性至关重要。值得一提的是,我们的模型具有很高的计算效率,因为我们只训练了一个投影层,使用了大约 500 万个对齐的图像-文本对。
相关阅读



评论
最新文章
热评文章
热门文章
-
 Grok--在线使用--马斯克的xAI开发的AI聊天机器人2023-11-13 阅读(444)
Grok--在线使用--马斯克的xAI开发的AI聊天机器人2023-11-13 阅读(444) -
 WoW--安装使用--美团发布的虚拟AI伙伴产品2023-11-13 阅读(706)
WoW--安装使用--美团发布的虚拟AI伙伴产品2023-11-13 阅读(706) -
 革命性突破!最全无闪烁AI视频制作教程 真正生产力 Stable diffusion + EbSynth + ControlNet2023-11-06 阅读(392)
革命性突破!最全无闪烁AI视频制作教程 真正生产力 Stable diffusion + EbSynth + ControlNet2023-11-06 阅读(392) -
 AI短视频剪辑Klap:给予OpenAI一键生成短视频,效率提高10倍2023-11-05 阅读(378)
AI短视频剪辑Klap:给予OpenAI一键生成短视频,效率提高10倍2023-11-05 阅读(378) -
 手把手教你如何用AI直接制作短视频2023-11-05 阅读(386)
手把手教你如何用AI直接制作短视频2023-11-05 阅读(386) -
AI文字/图片生成影片, 三款工具使用教程及实力测评: Runway gen2, pika, kaiber, 免费文本/图像转视频谁更强大 image to video, Runway vs pika2023-11-05 阅读(386)
-
 怎么用AI制作热门人文历史短视频在YouTube赚美金!历史题材自媒体素材用AI把文字图片生成视频教程,手把手教你短片剪辑实现网上赚钱2023-11-05 阅读(377)
怎么用AI制作热门人文历史短视频在YouTube赚美金!历史题材自媒体素材用AI把文字图片生成视频教程,手把手教你短片剪辑实现网上赚钱2023-11-05 阅读(377) -
 超逼真的AI数字人,一键免费生成教程!还能克隆你自己,用这2个网站即可轻松搞定!2023-11-05 阅读(387)
超逼真的AI数字人,一键免费生成教程!还能克隆你自己,用这2个网站即可轻松搞定!2023-11-05 阅读(387)
-
Grok--在线使用--马斯克的xAI开发的AI聊天机器人2023-11-13 阅读(444)
-
WoW--安装使用--美团发布的虚拟AI伙伴产品2023-11-13 阅读(706)
-
革命性突破!最全无闪烁AI视频制作教程 真正生产力 Stable diffusion + EbSynth + ControlNet2023-11-06 阅读(392)
-
 AI短视频剪辑Klap:给予OpenAI一键生成短视频,效率提高10倍2023-11-05 阅读(378)
AI短视频剪辑Klap:给予OpenAI一键生成短视频,效率提高10倍2023-11-05 阅读(378) -
 手把手教你如何用AI直接制作短视频2023-11-05 阅读(386)
手把手教你如何用AI直接制作短视频2023-11-05 阅读(386) -
 AI文字/图片生成影片, 三款工具使用教程及实力测评: Runway gen2, pika, kaiber, 免费文本/图像转视频谁更强大 image to video, Runway vs pika2023-11-05 阅读(386)
AI文字/图片生成影片, 三款工具使用教程及实力测评: Runway gen2, pika, kaiber, 免费文本/图像转视频谁更强大 image to video, Runway vs pika2023-11-05 阅读(386) -
 怎么用AI制作热门人文历史短视频在YouTube赚美金!历史题材自媒体素材用AI把文字图片生成视频教程,手把手教你短片剪辑实现网上赚钱2023-11-05 阅读(377)
怎么用AI制作热门人文历史短视频在YouTube赚美金!历史题材自媒体素材用AI把文字图片生成视频教程,手把手教你短片剪辑实现网上赚钱2023-11-05 阅读(377) -
 超逼真的AI数字人,一键免费生成教程!还能克隆你自己,用这2个网站即可轻松搞定!2023-11-05 阅读(387)
超逼真的AI数字人,一键免费生成教程!还能克隆你自己,用这2个网站即可轻松搞定!2023-11-05 阅读(387)
-
WoW--安装使用--美团发布的虚拟AI伙伴产品2023-11-13 阅读(706)
-
Grok--在线使用--马斯克的xAI开发的AI聊天机器人2023-11-13 阅读(444)
-
 革命性突破!最全无闪烁AI视频制作教程 真正生产力 Stable diffusion + EbSynth + ControlNet2023-11-06 阅读(392)
革命性突破!最全无闪烁AI视频制作教程 真正生产力 Stable diffusion + EbSynth + ControlNet2023-11-06 阅读(392) -
 Texta--在线使用--你的在线AI写作助手2023-11-05 阅读(391)
Texta--在线使用--你的在线AI写作助手2023-11-05 阅读(391) -
 超逼真的AI数字人,一键免费生成教程!还能克隆你自己,用这2个网站即可轻松搞定!2023-11-05 阅读(387)
超逼真的AI数字人,一键免费生成教程!还能克隆你自己,用这2个网站即可轻松搞定!2023-11-05 阅读(387) -
 AI文字/图片生成影片, 三款工具使用教程及实力测评: Runway gen2, pika, kaiber, 免费文本/图像转视频谁更强大 image to video, Runway vs pika2023-11-05 阅读(386)
AI文字/图片生成影片, 三款工具使用教程及实力测评: Runway gen2, pika, kaiber, 免费文本/图像转视频谁更强大 image to video, Runway vs pika2023-11-05 阅读(386) -
手把手教你如何用AI直接制作短视频2023-11-05 阅读(386)
-
 Friday AI--在线使用--智能写作助手2023-11-05 阅读(379)
Friday AI--在线使用--智能写作助手2023-11-05 阅读(379)