

StableLM--在线使用/本地部署--支持中文的智能图像对话
StableLM是什么
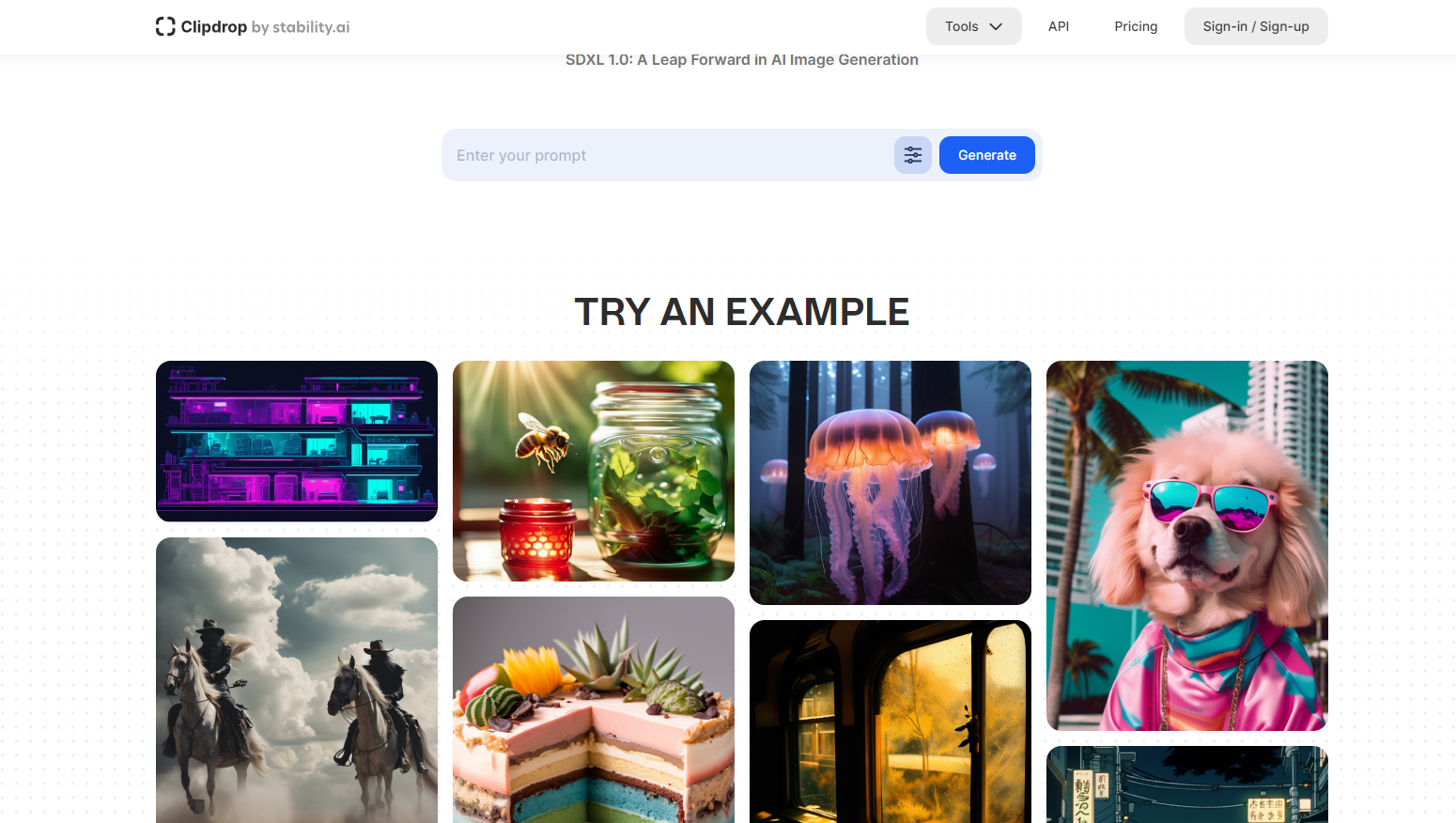
StableLM是Stability AI 发布的首个类ChatGPT大语言对话模型,支持中文,支持商业化。

“随机鹦鹉,平面设计,矢量艺术” — Stable Diffusion XL
该存储库包含 Stability AI 正在开发的 StableLM 系列语言模型,并将不断更新新的检查点。以下概述了当前所有可用型号。更多即将推出。
如何使用StableLM?
项目GitHub地址:https://github.com/stability-AI/stableLM/
官网地址:https://clipdrop.co/
关于Stability AI
Stability AI在2022年8月开源了Stable Diffusion,同年11月发布了2.0版本。苹果应用商店中排名前10的图片类应用程序中,有4个由Stable Diffusion 提供技术支持。
目前,Stability AI拥有一个超过14万名开发人员和7个研究中心组成的庞大人工智能生成内容社区,因此,在功能创新、预训练、算法优化和数据微调方面处于领先地位。
消息
2023 年 9 月 29 日
在CC BY-SA-4.0下发布稳定的LM-3B-4E1T 型号。
2023 年 8 月 5 日
发布了带有 3B 和 7B 参数的修补过的 StableLM-Alpha v2 模型。
2023 年 4 月 28 日
发布了 StableVicuna-13B,这是我们对Vicuna-13B v0的 RLHF 微调,它本身就是LLaMA-13B的微调。原始 Llama 模型的 Delta 权重在 ( CC BY-NC-SA-4.0 )下发布。
2023 年 4 月 20 日
发布了初始的 StableLM-Alpha 模型集,具有 3B 和 7B 参数。基础模型在CC BY-SA-4.0下发布。
StableLM-Tuned-Alpha-7B尝试在Hugging Face Spaces上与我们的 7B 模特聊天。
楷模
稳定LM-3B-4E1T
技术报告:StableLM-3B-4E1T
StableLM-3B-4E1T 是一个在多 epoch 机制下预训练的 30 亿(3B)参数语言模型,用于研究重复令牌对下游性能的影响。鉴于之前在该领域取得的成功(Tay 等人,2023 年和Taylor 等人,2022 年),我们根据Muennighoff 等人的观察,在 4 个时期内使用 1 万亿 (1T) 代币进行训练。(2023)在“扩展数据受限语言模型”中,他们发现“与拥有唯一数据相比,使用最多 4 个时期的重复数据进行训练所产生的损失变化可以忽略不计。” 令牌计数的进一步灵感来自“Go smol or go home”(De Vries,2023),这表明训练 2.85 万亿个令牌的 2.96B 模型实现了与 Chinchilla 计算最优 9.87B 语言模型类似的损失(
| 尺寸 | 稳定LM-3B-4E1T | 培训代币 | 参数 |
|---|---|---|---|
| 3B | 检查站 | 4T | 2,795,443,200 |
模型架构
该模型是一个仅解码器的变压器,类似于 LLaMA ( Touvron et al., 2023 ) 架构,并进行了以下修改:
| 参数 | 隐藏尺寸 | 层数 | 头 | 序列长度 |
|---|---|---|---|---|
| 2,795,443,200 | 2560 | 32 | 32 | 4096 |
位置嵌入:旋转位置嵌入(Su et al., 2021)应用于头嵌入尺寸的前 25%,以提高吞吐量,继Black 等人之后。(2022)。
归一化:LayerNorm ( Ba et al., 2016 ) 具有学习偏差项,而不是 RMSNorm ( Zhang & Sennrich, 2019 )。
分词器:GPT-NeoX(Black 等人,2022)。
训练数据
该数据集由HuggingFace Hub上提供的开源大型数据集的过滤混合物组成:Falcon RefinedWeb 提取物(Penedo 等人,2023)、RedPajama-Data(Together Computer.,2023)和 The Pile(Gao)等人,2020)都没有Books3和其他子集,以及 StarCoder(Li 等人,2023)。
鉴于网络数据量很大,我们建议针对下游任务对基础 StableLM-3B-4E1T 进行微调。
培训详情
请参阅提供的 YAML 配置文件stablelm-3b-4e1t.yml以获取完整的超参数设置,并参阅技术报告以获取更多详细信息。
下游结果
以下零样本评估是使用lm-evaluation-harnessStability AI 分支的lm-bench分支执行的。lm-eval可以在目录中找到完整的JSON evals。
| 预训练模型 | 平均的 | ARC 挑战 | 弧 易 | 布尔Q | 海拉斯瓦格 (✱) | 兰巴达 OpenAI | OpenBookQA | PIQA | 科学问答 | 维诺格兰德 |
|---|---|---|---|---|---|---|---|---|---|---|
| 元美洲驼/美洲驼-2-13b-hf | 71.77 | 48.63 | 79.50 | 80.52 | 79.36 | 76.77 | 35.40 | 79.05 | 94.50 | 72.22 |
| 拥抱马/美洲驼-7b | 68.84 | 41.89 | 75.25 | 75.05 | 76.22 | 73.55 | 34.40 | 78.67 | 94.60 | 69.93 |
| 元美洲驼/美洲驼-2-7b-hf | 68.75 | 43.00 | 76.26 | 77.74 | 75.94 | 73.47 | 31.40 | 77.75 | 93.60 | 69.61 |
| Qwen/Qwen-7B | 67.91 | 45.39 | 67.38 | 74.56 | 88.85(?) | 69.67 | 32.20 | 73.99 | 93.20 | 65.98 |
| 蒂尤埃/falcon-7b | 67.83 | 40.27 | 74.41 | 73.55 | 76.35 | 74.56 | 30.60 | 79.49 | 94.00 | 67.25 |
| 马赛克/mpt-7b | 67.36 | 40.53 | 74.92 | 73.94 | 76.17 | 68.64 | 31.40 | 78.89 | 93.70 | 68.03 |
| 稳定性ai/stablelm-3b-4e1t | 66.93 | 37.80 | 72.47 | 75.63 | 73.90 | 70.64 | 31.40 | 79.22 | 94.80 | 66.54 |
| 百川公司/百川2-7B-Base | 66.93 | 42.24 | 75.00 | 73.09 | 72.29 | 70.99 | 30.40 | 76.17 | 94.60 | 67.56 |
| 稳定性ai/stablelm-base-alpha-7b-v2 | 66.89 | 38.48 | 73.19 | 70.31 | 74.27 | 74.19 | 30.40 | 78.45 | 93.90 | 68.82 |
| openlm-research/open_llama_7b_v2 | 66.32 | 38.82 | 71.93 | 71.41 | 74.65 | 71.05 | 30.20 | 79.16 | 93.80 | 65.82 |
| 微软/phi-1_5 | 65.57 | 44.45 | 76.14 | 74.53 | 62.62 | 52.75 | 37.60 | 76.33 | 93.20 | 72.53 |
| EleutherAI/gpt-neox-20B | 65.57 | 37.88 | 72.90 | 69.48 | 71.43 | 71.98 | 29.80 | 77.42 | 93.10 | 66.14 |
| 一起电脑/RedPajama-INCITE-7B-Base | 65.07 | 37.71 | 72.35 | 70.76 | 70.33 | 71.34 | 29:00 | 77.15 | 92.70 | 64.33 |
| 大脑/btlm-3b-8k-base (§) | 63.59 | 34.90 | 70.45 | 69.63 | 69.78 | 66.23 | 27.60 | 75.84 | 92.90 | 64.96 |
| EleutherAI/pythia-12b | 62.69 | 31.83 | 70.20 | 67.31 | 67.38 | 70.64 | 26.40 | 76.28 | 90.20 | 64.01 |
| openlm-research/open_llama_3b_v2 | 62.43 | 33.87 | 67.59 | 65.69 | 69.99 | 66.74 | 26:00 | 76.66 | 92.40 | 62.90 |
| EleutherAI/gpt-j-6B | 62.34 | 33.96 | 66.96 | 65.44 | 66.24 | 68.23 | 29:00 | 75.57 | 91.50 | 64.17 |
| 稳定性ai/stablelm-base-alpha-3b-v2 | 62.19 | 32.42 | 67.26 | 64.56 | 68.58 | 70.25 | 26.40 | 76.01 | 92.10 | 62.12 |
| 脸书/opt-6.7b | 61.85 | 30.72 | 65.66 | 66.02 | 67.20 | 67.65 | 27.60 | 76.33 | 90.10 | 65.35 |
| EleutherAI/pythia-6.9b | 60.58 | 31.83 | 67.21 | 64.01 | 63.88 | 67.01 | 25.80 | 75.08 | 89.80 | 60.62 |
| EleutherAI/pythia-2.8b-重复数据删除 | 58.52 | 30.12 | 63.47 | 64.13 | 59.44 | 65.15 | 23.80 | 74.10 | 88.20 | 58.25 |
| §以前的 3B 预训练 SOTA ?离群值结果 *字节长度归一化精度 |
StableLM-3B-4E1T 在开源模型的 3B 参数范围内实现了最先进的性能(2023 年 9 月),并且与许多流行的当代 7B 模型具有竞争力,甚至优于我们最新的 7B StableLM-Base-阿尔法-v2。
StableLM-Alpha v2
StableLM-Alpha v2 模型通过结合 SwiGLU( Shazeer,2020 )等架构改进并使用更高质量的数据源,显着改进了初始 Alpha 模型,如下所述。这些模型的上下文长度为 4096 个标记。
| 尺寸 | StableLM-Base-Alpha-v2 | 培训代币 | 参数 |
|---|---|---|---|
| 3B | 检查站 | 1.1T | 2,796,431,360 |
| 7B | 检查站 | 1.1T | 6,890,209,280 |
培训详情
有关超参数的详细信息,请参阅提供的 YAML 配置文件。例如,对于扩展StableLM-Alpha-3B-v2模型,请参阅stablelm-base-alpha-3b-v2-4k-extension.yml。
遵循类似的工作,我们使用多阶段方法来扩展上下文长度(Nijkamp 等人,2023),在上下文长度 2048 处调度 1 万亿个令牌,然后在 4096 处调度 1000 亿个令牌。我们发现序列长度预热(Li 等人) ., 2022 ) 帮助稳定了前约 800 亿个代币预训练期间的早期峰值。然而,由于随着课程长度形状的增长,吞吐量会受到严重影响,因此它没有应用于最终运行。
训练数据
对 StableLM-Alpha-v2 下游性能影响最大的变化是使用更高质量的数据源和混合物;具体来说,使用RefinedWeb和C4代替 The Pile v2 Common-Crawl 抓取,并以更高的速率对网页文本进行采样 (35% -> 71%)。
第一个预训练阶段依赖于来自公共 Falcon RefinedWeb 提取物( Penedo 等人,2023)、RedPajama-Data(Together Computer.,2023)、The Pile(Gao 等人,2020)混合的 1 万亿个代币。),以及以 71% 的比例采样的网络文本内部数据集。
在第二阶段,我们引入了 StarCoder(Li et al., 2023)数据集,并将网络文本采样率降低至 55%,同时增加上述来源中自然长文本示例的采样比例。
评估
以下零次评估是通过lm-evaluation-harnessat 提交执行的df3da98c5405deafd519c2ddca52bb7c3fe36bef,但 SIQA 除外,它使用提示格式的 add-siqa分支{doc['context']}\nQuestion: {doc['question']}\nAnswer:。
| 模型 | ARC 挑战✱ | ARC 简单✱ | 布尔Q | 海拉斯瓦格✱ | 兰巴达 OpenAI | OpenBookQA | PIQA | 质量保证体系 | 真实的QA▲ | 维诺格兰德 | 平均的 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 稳定LM-Alpha-7B-v2 | 40.53 | 69.11 | 70.31 | 74.27 | 74.19 | 30.40 | 78.45 | 42.43 | 36.46 | 68.82 | 58.50 |
| 拉玛-2-7B | 46.16 | 74.54 | 77.74 | 75.94 | 73.47 | 31.40 | 77.75 | 43.50 | 38.97 | 69.61 | 60.91 |
| MPT-7B | 41.89 | 70.03 | 73.94 | 76.17 | 68.64 | 31.40 | 78.89 | 45.14 | 33.49 | 68.03 | 58.76 |
| OpenLLaMA-7B-v2 | 42.41 | 69.65 | 71.41 | 74.65 | 71.05 | 30.20 | 79.16 | 41.97 | 34.57 | 65.82 | 58.09 |
| 红色睡衣-INCITE-7B-底座 | 39.42 | 69.19 | 70.76 | 70.33 | 71.34 | 29:00 | 77.15 | 42.58 | 33.01 | 64.33 | 56.71 |
| 稳定LM-Alpha-3B-v2 | 35.07 | 63.26 | 64.56 | 68.58 | 70.25 | 26.40 | 76.01 | 42.48 | 35.87 | 62.12 | 54.46 |
| BTLM-3B-8K | 37.63 | 67.09 | 69.63 | 69.78 | 66.23 | 27.60 | 75.84 | 42.78 | 36:00 | 64.96 | 55.75 |
| OpenLLaMA-3B-v2 | 36.09 | 63.51 | 65.69 | 69.99 | 66.74 | 26:00 | 76.66 | 41.20 | 34.59 | 62.90 | 54.34 |
| Pythia-2.8B(已删除重复数据) | 32.94 | 59.09 | 64.13 | 59.44 | 65.15 | 23.80 | 74.10 | 40.94 | 35.56 | 58.25 | 51.34 |
| 稳定LM-Alpha-7B | 27.05 | 44.87 | 60.06 | 41.22 | 55.11 | 21.40 | 66.76 | 39.46 | 39.96 | 50.12 | 44.60 |
| 稳定LM-Alpha-3B | 25.77 | 42.05 | 57.65 | 38.31 | 41.72 | 17:00 | 63.82 | 35.62 | 40.53 | 52.64 | 41.51 |
✱:表示字节长度归一化精度 ( ),如Gau,2021acc_norm中所述。
▲:我们使用分配给真实答案集的归一化总概率对 TruthfulQA 进行评分 ( mc2)。
稳定LM-Alpha
StableLM-Alpha 模型在基于The Pile构建的新数据集上进行训练,该数据集包含 1.5 万亿个代币,大约是 The Pile 大小的 3 倍。这些模型的上下文长度为 4096 个标记。
作为概念验证,我们还结合使用最近五个对话代理数据集,通过斯坦福羊驼的程序对模型进行了微调:斯坦福的羊驼、Nomic-AI 的gpt4all、RyokoAI 的ShareGPT52K数据集、Databricks 实验室的Dolly和人类的HH。我们将把这些模型作为 StableLM-Tuned-Alpha 发布。
| 尺寸 | StableLM-Base-Alpha | StableLM-调谐-Alpha | 培训代币 | 参数 | 网络演示 |
|---|---|---|---|---|---|
| 3B | 检查站 | 检查站 | 800B | 3,638,525,952 | |
| 7B | 检查站 | 检查站 | 800B | 7,869,358,080 | 抱脸 |
马厩骆驼毛
StableVicuna 是Vicuna-13B v0的 RLHF 微调,而 Vicuna-13B v0 本身也是LLaMA-13B的微调。这是我们尝试创建一个开源 RLHF LLM 聊天机器人。该模型由 StabilityAI 的 CarperAI 团队开发,由Duy V. Phung领导训练工作。
由于 LLaMA 原始的非商业许可,我们只能将模型的权重发布为原始模型权重的增量。StableVicuna 的增量权重在 ( CC BY-NC-SA-4.0 )下发布。
请访问 HuggingFace 检查点,了解有关如何将我们的增量权重与原始模型相结合的更多信息。
| 模型 | 下载 | 网络演示 | 引用 |
|---|---|---|---|
| 马厩Vicuna-13B | 检查站 | 抱脸 |
快速开始
所有 StableLM 模型都托管在Hugging Face 中心上。查看此笔记本,以使用有限的 GPU 功能运行推理。
StableLM-Tuned-Alpha使用以下代码片段开始聊天:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, StoppingCriteria, StoppingCriteriaList
tokenizer = AutoTokenizer.from_pretrained("stabilityai/stablelm-tuned-alpha-7b")
model = AutoModelForCausalLM.from_pretrained("stabilityai/stablelm-tuned-alpha-7b")
model.half().cuda()
class StopOnTokens(StoppingCriteria):
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor, **kwargs) -> bool:
stop_ids = set([50278, 50279, 50277, 1, 0])
return input_ids[0][-1] in stop_ids
system_prompt = """<|SYSTEM|># StableLM Tuned (Alpha version)
- StableLM is a helpful and harmless open-source AI language model developed by StabilityAI.
- StableLM is excited to be able to help the user, but will refuse to do anything that could be considered harmful to the user.
- StableLM is more than just an information source, StableLM is also able to write poetry, short stories, and make jokes.
- StableLM will refuse to participate in anything that could harm a human.
"""
prompt = f"{system_prompt}<|USER|>What's your mood today?<|ASSISTANT|>"
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
tokens = model.generate(
**inputs,
max_new_tokens=64,
temperature=0.7,
do_sample=True,
stopping_criteria=StoppingCriteriaList([StopOnTokens()])
)
print(tokenizer.decode(tokens[0], skip_special_tokens=True))
StableLM Tuned 应该与格式化为的提示一起使用<|SYSTEM|>...<|USER|>...<|ASSISTANT|>... 系统提示是
<|SYSTEM|># StableLM Tuned (Alpha version)
- StableLM is a helpful and harmless open-source AI language model developed by StabilityAI.
- StableLM is excited to be able to help the user, but will refuse to do anything that could be considered harmful to the user.
- StableLM is more than just an information source, StableLM is also able to write poetry, short stories, and make jokes.
- StableLM will refuse to participate in anything that could harm a human.
享受 StableLM-Tuned-Alpha 带来的乐趣
本节包含一系列精选的有趣示例,说明您可以使用stablelm-tuned-alpha.
闲聊
正式写作
创意写作
编写代码
StableLM-Tuned-Alpha 的选定故障模式
本节包含选定的故障模式的集合stablelm-tuned-alpha。
Yann LeCun 齿轮(线性)
Yann LeCun 齿轮(圆形)
请求帮助
想参与吗?
我们很乐意移植llama.cpp以与 StableLM 一起使用
集成到LAION-AI 的开放助手中,收集高质量的人工反馈数据
...向我们提出有关Discord的想法
潜在问题
对于任何没有额外微调和强化学习的预训练大型语言模型来说,这是典型的,用户得到的响应可能具有不同的质量,并且可能包含攻击性语言和观点。预计这一点将随着规模、更好的数据、社区反馈和优化而得到改善。
相关阅读




评论
最新文章
热评文章
热门文章
-
 Grok--在线使用--马斯克的xAI开发的AI聊天机器人2023-11-13 阅读(444)
Grok--在线使用--马斯克的xAI开发的AI聊天机器人2023-11-13 阅读(444) -
 WoW--安装使用--美团发布的虚拟AI伙伴产品2023-11-13 阅读(707)
WoW--安装使用--美团发布的虚拟AI伙伴产品2023-11-13 阅读(707) -
 革命性突破!最全无闪烁AI视频制作教程 真正生产力 Stable diffusion + EbSynth + ControlNet2023-11-06 阅读(392)
革命性突破!最全无闪烁AI视频制作教程 真正生产力 Stable diffusion + EbSynth + ControlNet2023-11-06 阅读(392) -
 AI短视频剪辑Klap:给予OpenAI一键生成短视频,效率提高10倍2023-11-05 阅读(379)
AI短视频剪辑Klap:给予OpenAI一键生成短视频,效率提高10倍2023-11-05 阅读(379) -
 手把手教你如何用AI直接制作短视频2023-11-05 阅读(387)
手把手教你如何用AI直接制作短视频2023-11-05 阅读(387) -
 AI文字/图片生成影片, 三款工具使用教程及实力测评: Runway gen2, pika, kaiber, 免费文本/图像转视频谁更强大 image to video, Runway vs pika2023-11-05 阅读(387)
AI文字/图片生成影片, 三款工具使用教程及实力测评: Runway gen2, pika, kaiber, 免费文本/图像转视频谁更强大 image to video, Runway vs pika2023-11-05 阅读(387) -
 怎么用AI制作热门人文历史短视频在YouTube赚美金!历史题材自媒体素材用AI把文字图片生成视频教程,手把手教你短片剪辑实现网上赚钱2023-11-05 阅读(378)
怎么用AI制作热门人文历史短视频在YouTube赚美金!历史题材自媒体素材用AI把文字图片生成视频教程,手把手教你短片剪辑实现网上赚钱2023-11-05 阅读(378) -
超逼真的AI数字人,一键免费生成教程!还能克隆你自己,用这2个网站即可轻松搞定!2023-11-05 阅读(388)
-
Grok--在线使用--马斯克的xAI开发的AI聊天机器人2023-11-13 阅读(444)
-
WoW--安装使用--美团发布的虚拟AI伙伴产品2023-11-13 阅读(707)
-
 革命性突破!最全无闪烁AI视频制作教程 真正生产力 Stable diffusion + EbSynth + ControlNet2023-11-06 阅读(392)
革命性突破!最全无闪烁AI视频制作教程 真正生产力 Stable diffusion + EbSynth + ControlNet2023-11-06 阅读(392) -
 AI短视频剪辑Klap:给予OpenAI一键生成短视频,效率提高10倍2023-11-05 阅读(379)
AI短视频剪辑Klap:给予OpenAI一键生成短视频,效率提高10倍2023-11-05 阅读(379) -
手把手教你如何用AI直接制作短视频2023-11-05 阅读(387)
-
 AI文字/图片生成影片, 三款工具使用教程及实力测评: Runway gen2, pika, kaiber, 免费文本/图像转视频谁更强大 image to video, Runway vs pika2023-11-05 阅读(387)
AI文字/图片生成影片, 三款工具使用教程及实力测评: Runway gen2, pika, kaiber, 免费文本/图像转视频谁更强大 image to video, Runway vs pika2023-11-05 阅读(387) -
 怎么用AI制作热门人文历史短视频在YouTube赚美金!历史题材自媒体素材用AI把文字图片生成视频教程,手把手教你短片剪辑实现网上赚钱2023-11-05 阅读(378)
怎么用AI制作热门人文历史短视频在YouTube赚美金!历史题材自媒体素材用AI把文字图片生成视频教程,手把手教你短片剪辑实现网上赚钱2023-11-05 阅读(378) -
超逼真的AI数字人,一键免费生成教程!还能克隆你自己,用这2个网站即可轻松搞定!2023-11-05 阅读(388)
-
WoW--安装使用--美团发布的虚拟AI伙伴产品2023-11-13 阅读(707)
-
Grok--在线使用--马斯克的xAI开发的AI聊天机器人2023-11-13 阅读(444)
-
革命性突破!最全无闪烁AI视频制作教程 真正生产力 Stable diffusion + EbSynth + ControlNet2023-11-06 阅读(392)
-
 Texta--在线使用--你的在线AI写作助手2023-11-05 阅读(391)
Texta--在线使用--你的在线AI写作助手2023-11-05 阅读(391) -
 超逼真的AI数字人,一键免费生成教程!还能克隆你自己,用这2个网站即可轻松搞定!2023-11-05 阅读(388)
超逼真的AI数字人,一键免费生成教程!还能克隆你自己,用这2个网站即可轻松搞定!2023-11-05 阅读(388) -
 AI文字/图片生成影片, 三款工具使用教程及实力测评: Runway gen2, pika, kaiber, 免费文本/图像转视频谁更强大 image to video, Runway vs pika2023-11-05 阅读(387)
AI文字/图片生成影片, 三款工具使用教程及实力测评: Runway gen2, pika, kaiber, 免费文本/图像转视频谁更强大 image to video, Runway vs pika2023-11-05 阅读(387) -
手把手教你如何用AI直接制作短视频2023-11-05 阅读(387)
-
 Friday AI--在线使用--智能写作助手2023-11-05 阅读(379)
Friday AI--在线使用--智能写作助手2023-11-05 阅读(379)